PhotoVerse: Tuning-Free Image Customization with Text-to-Image Diffusion Models
✅ only one facial photograph. ✅ no test-time tuning. ✅ demonstrate exceptional ID preservation and editability.
✅ only one facial photograph. ✅ no test-time tuning. ✅ demonstrate exceptional ID preservation and editability.
Gallery
Here we present the highest-quality generated results achieved by leveraging a single reference image and a variety of prompts.



Methodology
Personalized text-to-image generation has emerged as a powerful and sought-after tool, empowering users to create customized images based on their specific concepts and prompts. However, existing approaches to personalization encounter multiple challenges, including long tuning times, large storage requirements, the necessity for multiple input images per identity, and limitations in preserving identity and editability.
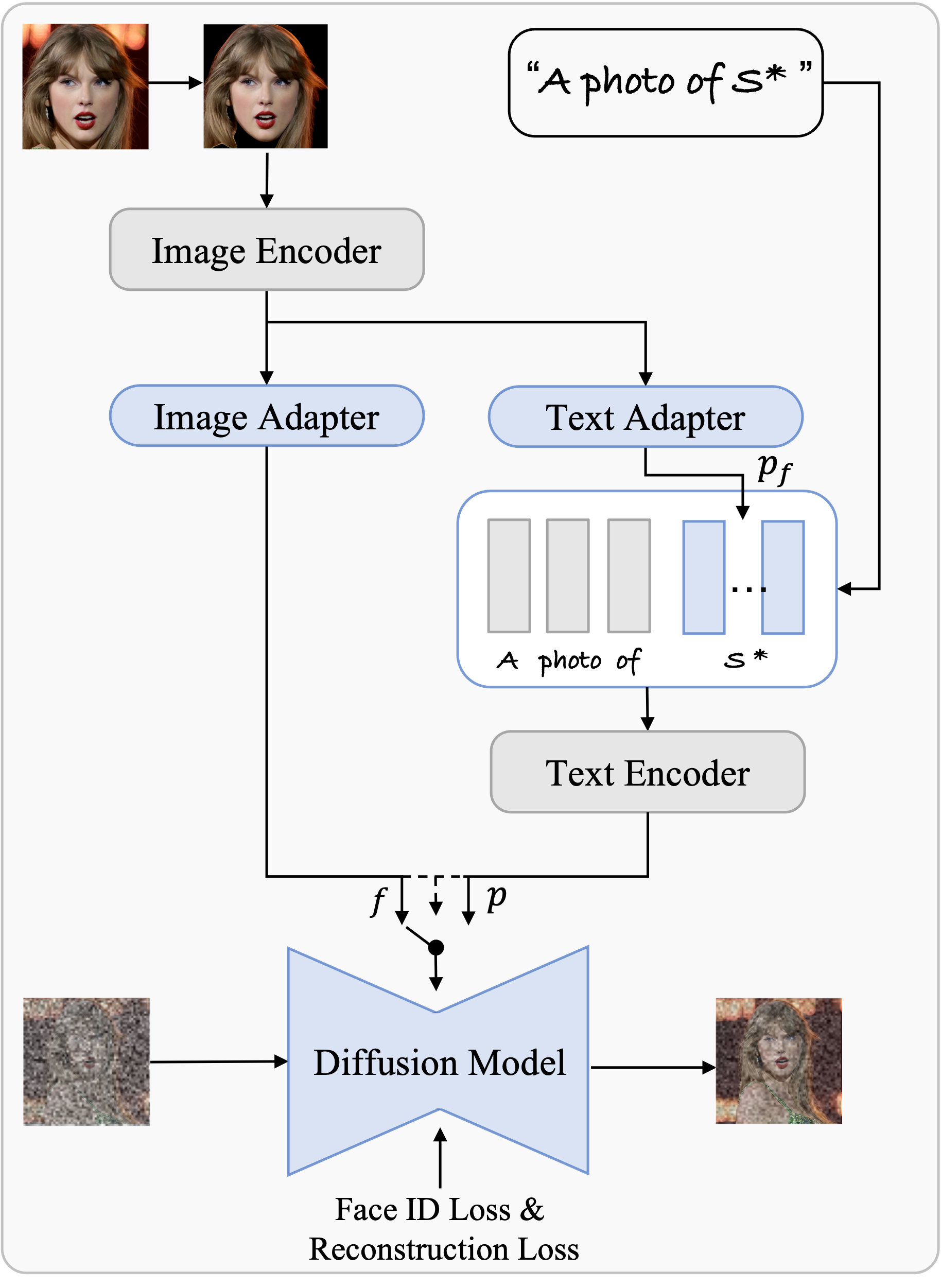
To address these obstacles, we present PhotoVerse, an innovative methodology that incorporates a dual-branch conditioning mechanism in both text and image domains, providing effective control over the image generation process.
Furthermore, we introduce facial identity loss as a novel component to enhance the preservation of identity during training. Remarkably, our proposed PhotoVerse eliminates the need for test time tuning and relies solely on a single facial photo of the target identity, significantly reducing the resource cost associated with image generation. After a single training phase, our approach enables generating high-quality images within only a few seconds. Moreover, our method can produce diverse images that encompass various scenes and styles.
Comparisons to Prior Work
Here we present the comparisons with prior personalization methods. The results of prior methods are directly taken from ProFusion.

Our proposed PhotoVerse shows superior performance in preserving identity attributes and generating high-quality images. Notice that DreamBooth, Textual Inversion, E4T and ProFusion require an additional stage of fine-tuning on the provided reference image prior to generation. In contrast, our PhotoVerse is tuning-free and boasts rapid generation speed, offering a distinct advantage in terms of efficiency and user convenience.
BibTeX
@misc{chen2023photoverse,
title={PhotoVerse: Tuning-Free Image Customization with Text-to-Image Diffusion Models},
author={Chen, Li and Zhao, Mengyi and Liu, Yiheng and Ding, Mingxu and Song, Yangyang and Wang, Shizun and Wang, Xu and Yang, Hao and Liu, Jing and Du, Kang and others},
booktitle={arXiv preprint arxiv:2309.05793},
year={2023},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Project page template is borrowed from AnimateDiff.
If you want an image removed from this page or have other requests, please contact us at zhaomengyi@buaa.edu.cn